




Dokumentenmanagement-System (DMS) mit Scanbot verbinden: Immer dann, wenn physische Dokumente in ein DMS müssen, kommen Apps ins Spiel. Eine sehr beliebte App für iPhone, iPad und Android ist Scanbot. Sie ist weltweit bei über 200 Unternehmen im Einsatz und auch bei unseren Kunden. Oliver Schulze erklärt in 10 Schritten, wie Sie den Scanbot mit unserem Open-Source-DMS/ECM agorum core verbinden und wie beispielhaft eine Rechnung vollautomatisiert verarbeitet wird.
Dokumentenmanagement mit Scanbot verbinden
In diesem Blogbeitrag zeige ich Ihnen, wie Sie die App Scanbot, verfügbar für iPhone, iPad und Android, zusammen mit dem Dokumentenmanagement System agorum core verwenden.
Darüber hinaus zeige ich Ihnen am Beispiel einer Rechnung, wie die komplette automatische Verarbeitung nach dem Scan funktioniert: vom vollautomatischen Auslesen der Metadaten und Rechnungspositionen bis hin zur Freigabe der Rechnung und Übergabe an ein Warenwirtschaftssystem.
10 Schritte zum Ziel
- Den Scanbot mit agorum core verbinden
- Vollautomatische Verarbeitung: Scaneingang für docform einrichten
- Es kann losgehen: der erste Scan
- Speicherort der Scanbot-Daten
- Weiteres Vorgehen nach der Archivierung der Dokumente
- Vollautomatische Verarbeitung der gescannten Dokumente
- Das Dokument “einmalig” trainieren
- Positionsdaten auslesen
- Automatisch erfasste Dokumente manuell prüfen
- Weiteres Vorgehen nach der Erfassung
1.) Den Scanbot mit agorum core verbinden
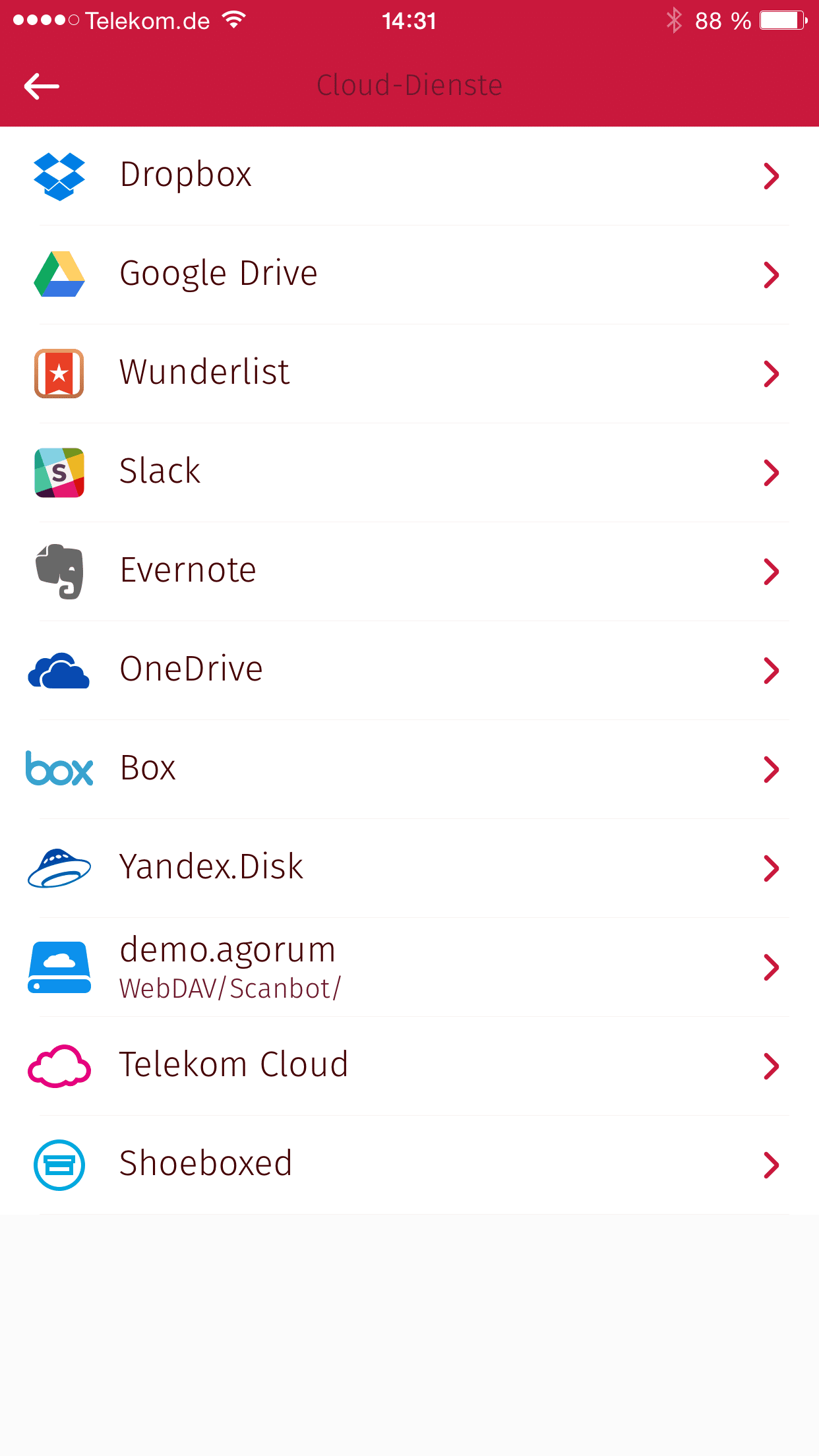
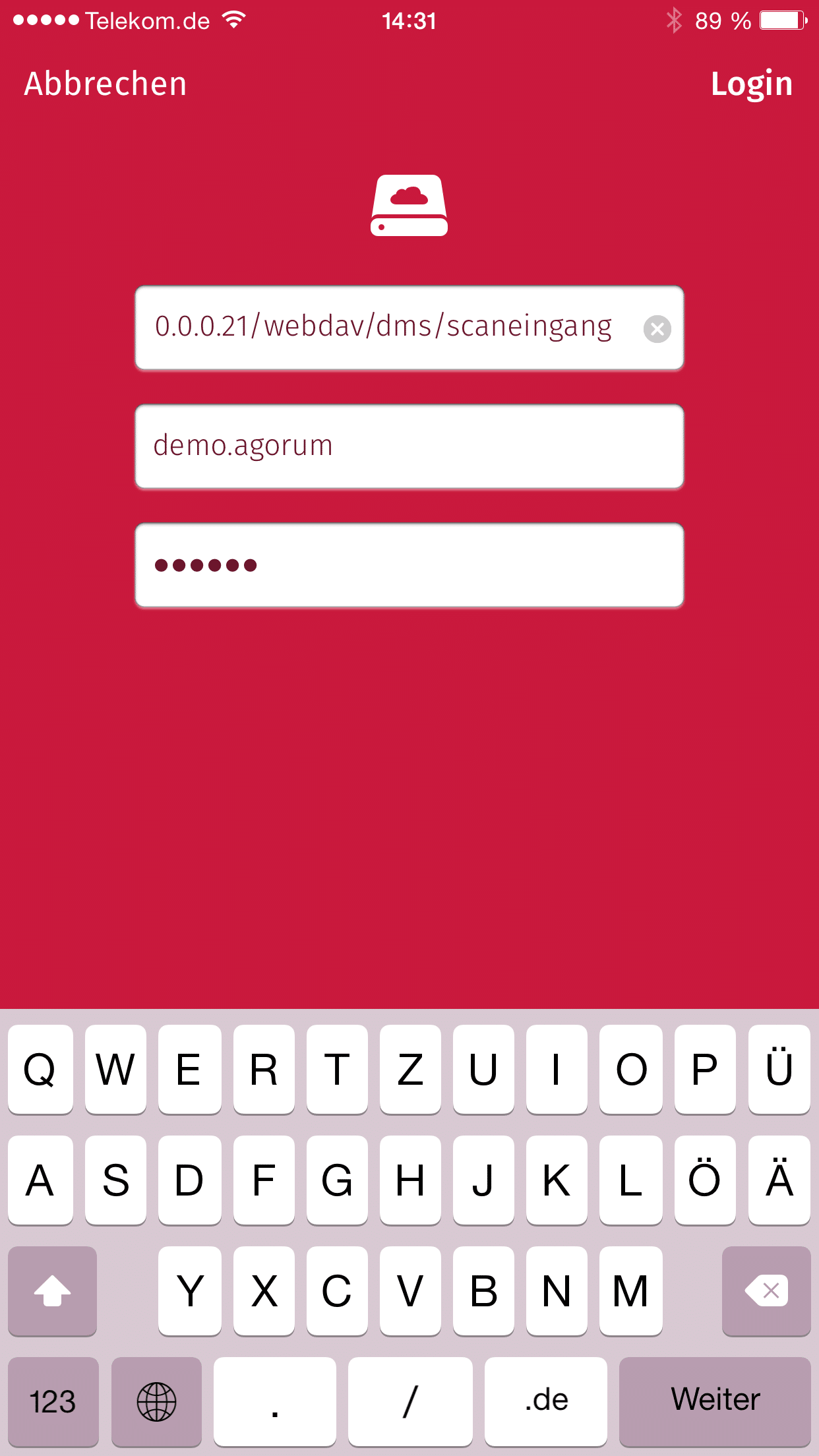
- Zuallererst verbinde ich den Scanbot mit agorum core über das in agorum core integrierte WebDAV-Protokoll. Dazu wechsele ich in die Einstellungen des Scanbots und wähle “Cloud-Dienste > WebDAV”. Im obigen Beispiel lautet der Eintrag “demo.agorum”.
- Ich gebe die Zugangsdaten zu agorum core ein.
- Den Dokumentenbereich von agorum core finde ich unter der Freigabe “dms”. Gibt es dort beispielsweise ein Verzeichnis “Scaneingang” direkt im Bereich “Dateien” von agorum core, so lautet die WebDAV-Adresse: https://ihr-server/webdav/dms/Scaneingang
- Ich gebe den Benutzernamen und das Passwort eines Benutzers ein, der Schreibrechte für dieses Verzeichnis besitzt.
Ich aktiviere im Scanbot den automatischen Upload in das Scanziel, damit ein gescanntes Dokument automatisch direkt im DMS landet.
2.) Vollautomatische Verarbeitung: Scaneingang für docform einrichten
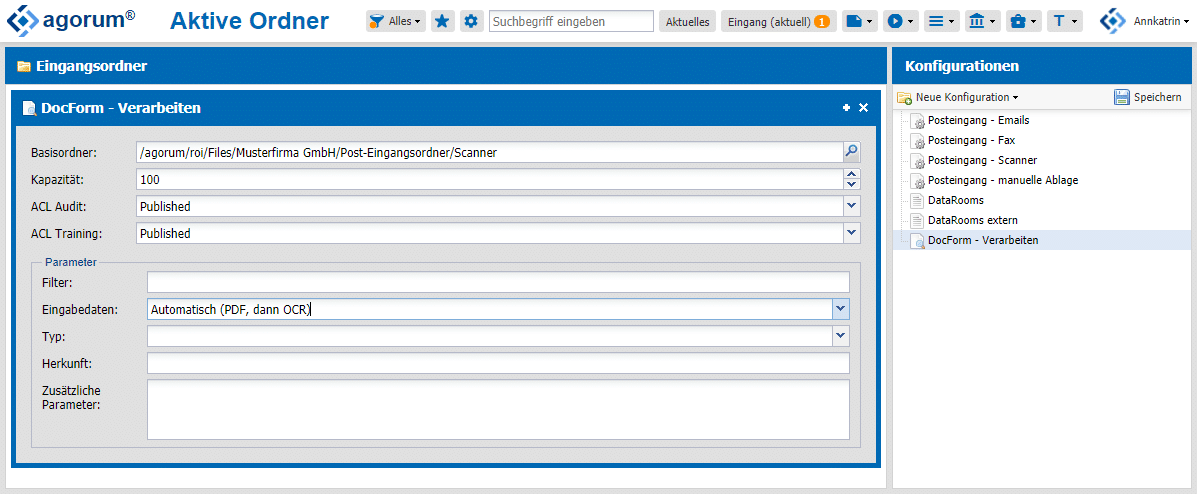
Im nächsten Schritt kennzeichne ich den Scaneingangs-Ordner in agorum core als “Aktiven Ordner”, sodass darin eingehende Dokumente automatisch durch docform verarbeitet werden.
- Dazu öffne ich “Aktive Ordner” über die Startseite von agorum core.
- Dort richte ich eine neue “docform – Verarbeiten”-Konfiguration ein und benenne diese entsprechend.
- Bei Basisordner wähle ich den zuvor eingerichteten Scaneingangsordner aus, auf den Scanbot verbunden wurde.
- Bei Eingabedaten wähle ich “Nur OCR”, sodass eine OCR-Erkennung durch den Server auf jeden Fall durchgeführt wird.
- Ich speichere die Konfiguration.
3.) Es kann los gehen: der erste Scan

Als Nächstes kann ich den Scanbot mit dem Scannen beginnen lassen.
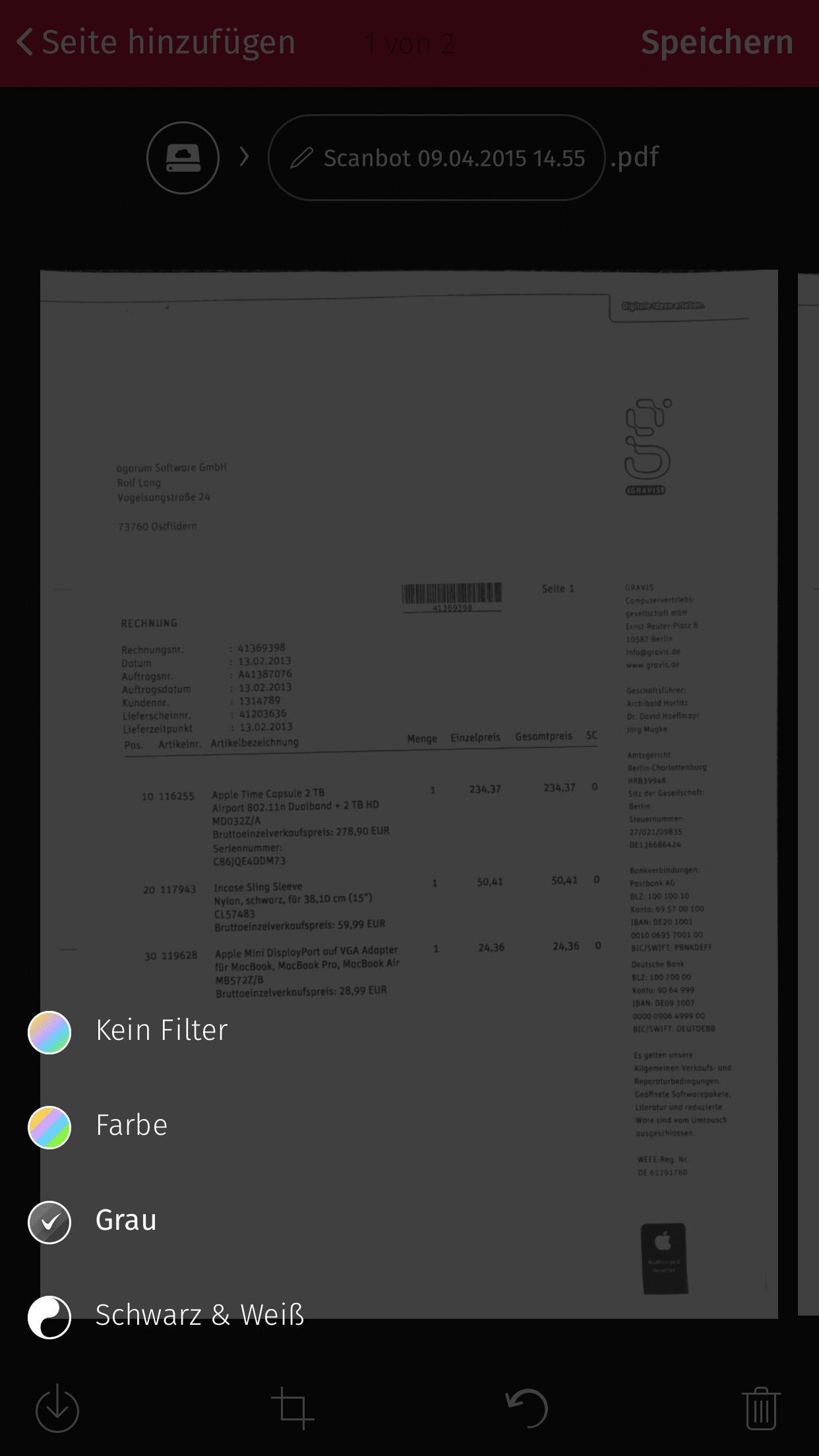
Das gescannte Dokument kann am besten verarbeitet werden, wenn es als PDF-Datei mit Graustufen gespeichert wird. Eine OCR -Erkennung über Scanbot selbst ist nicht notwendig, da im DMS bereits eine OCR enthalten ist. Das führt bei Scanbot auch dazu, dass die Verarbeitung wesentlich schneller abläuft.
Nach dem Speichern vergebe ich einen beliebigen Namen. Daraufhin wird das Dokument durch Scanbot automatisch in den Scaneingang von agorum core hochgeladen.
4.) Speicherort der Scanbot-Daten
Oft werden wir gefragt: Wo speichert der Scanbot seine Daten? In unserem Fall haben wir Scanbot mit agorum core über den integrierten Fileserver (via WebDAV) gekoppelt. Wenn dies nicht der Fall ist, werden die gescannten Daten im Ordner “Eigene Dateien” abgelegt, sortiert in Unterordnern nach Scandatum.
5.) Weiteres Vorgehen nach der Archivierung der Dokumente
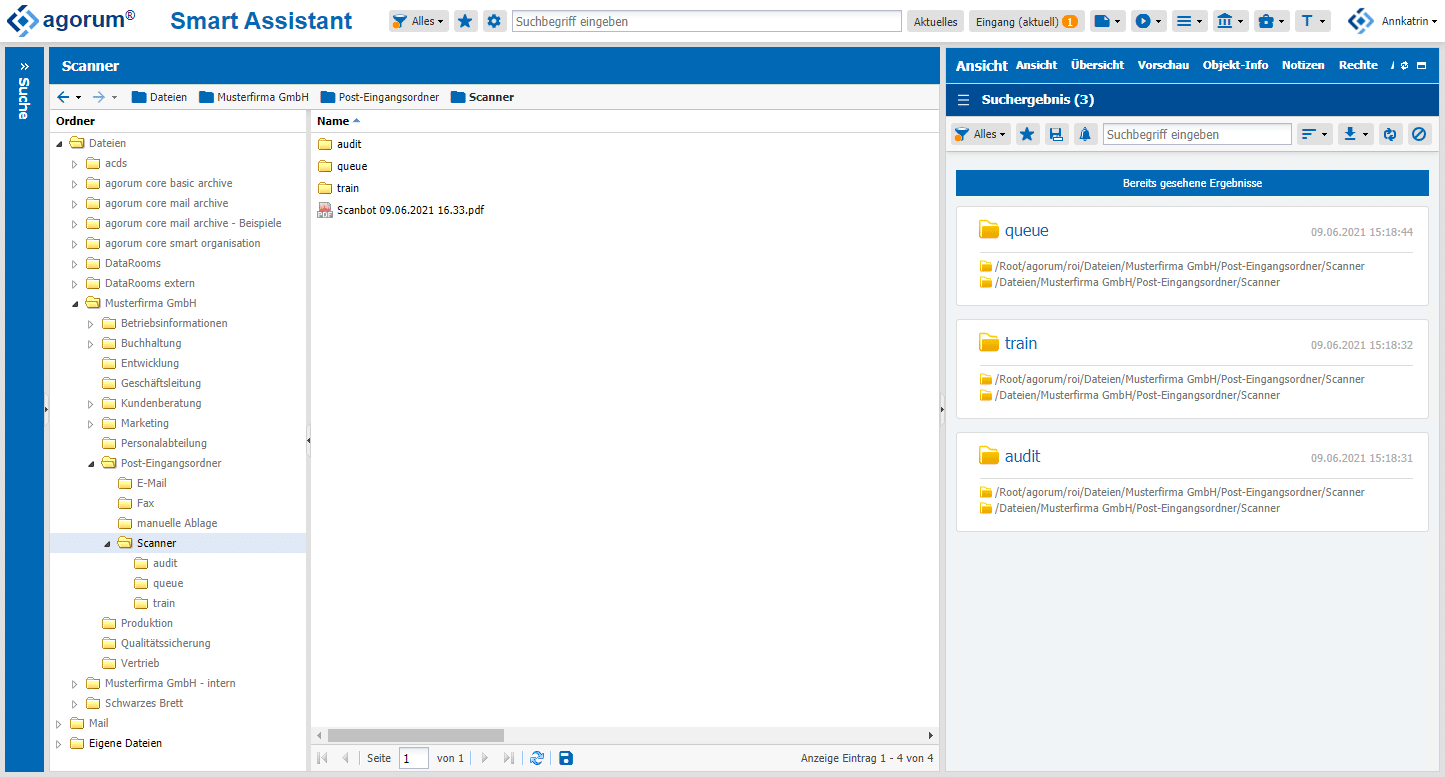
6.) Vollautomatische Verarbeitung der gescannten Dokumente
Für die automatische Erfassung der Metadaten aus dem gescannten Dokument öffne ich das Modul agorum core docform.
Dort wähle ich den Ordner “Scanbot Eingang”, den ich zuvor unter “Aktive Ordner” definiert habe.
Daraufhin erscheint das Dokument beim allerersten Mal unter “Dokumente” auf der linken Seite und hat den Status “Training”, da docform im Moment noch nicht weiß, was es mit diesem Dokument anfangen soll.
7.) Das Dokument "einmalig" trainieren
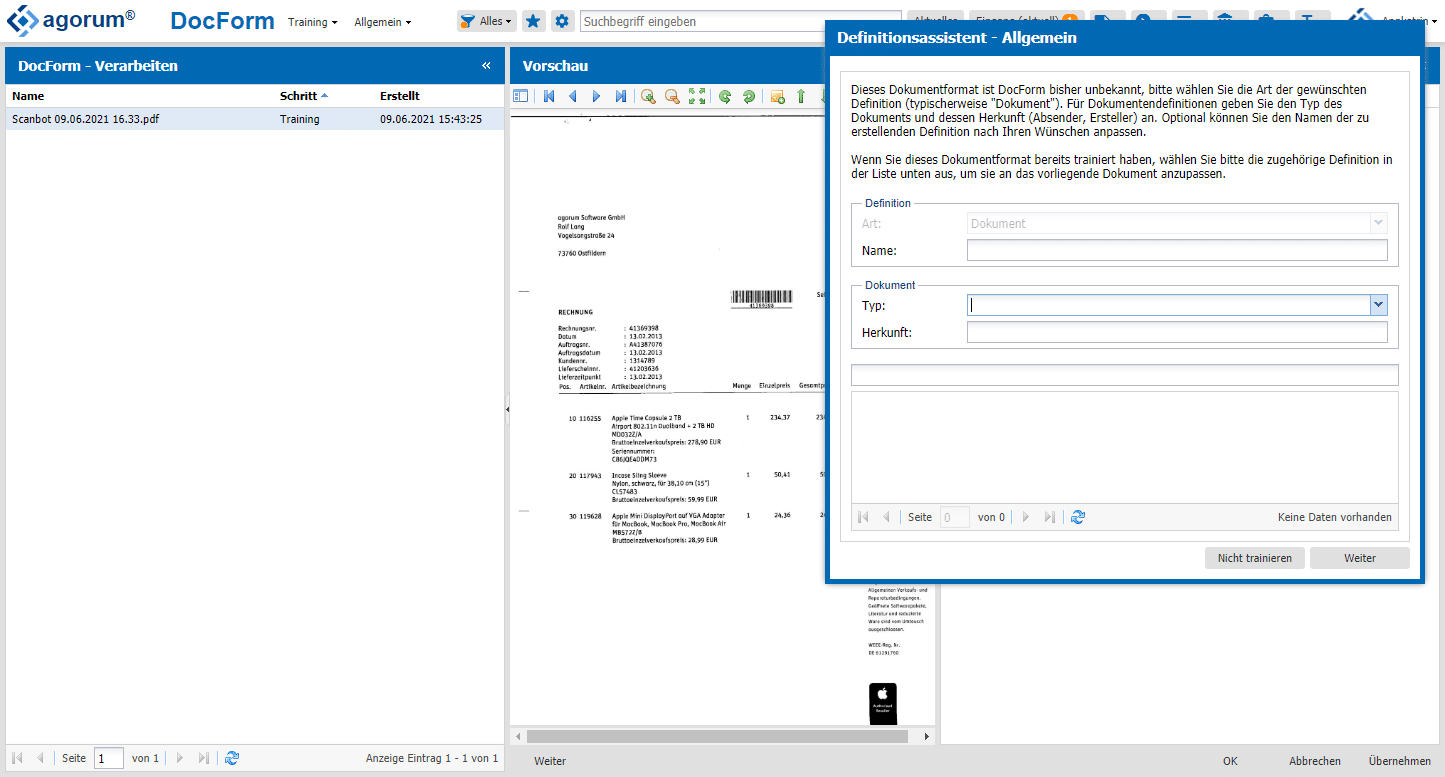
Bei einem unbekannten Dokumententyp fragt docform nach, was es mit dem Dokument anfangen soll. Durch den in docform integrierten Assistenten funktioniert die Definition sehr einfach. Das Training erfolgt pro Dokumententyp nur einmal. Wird ein weiteres Dokument verarbeitet, das zum definierten Training passt, erfolgt die Verarbeitung vollautomatisch.
- Dokumententyp auswählen
Zuallererst wähle ich aus, um welche Art Dokument es sich handelt. Die Dokumententypen werden einmalig zentral über das agorum core-Modul “docform Dokumententypen” definiert. Dabei wird hinterlegt, aus welchen Metadaten der jeweilige Dokumententyp besteht.
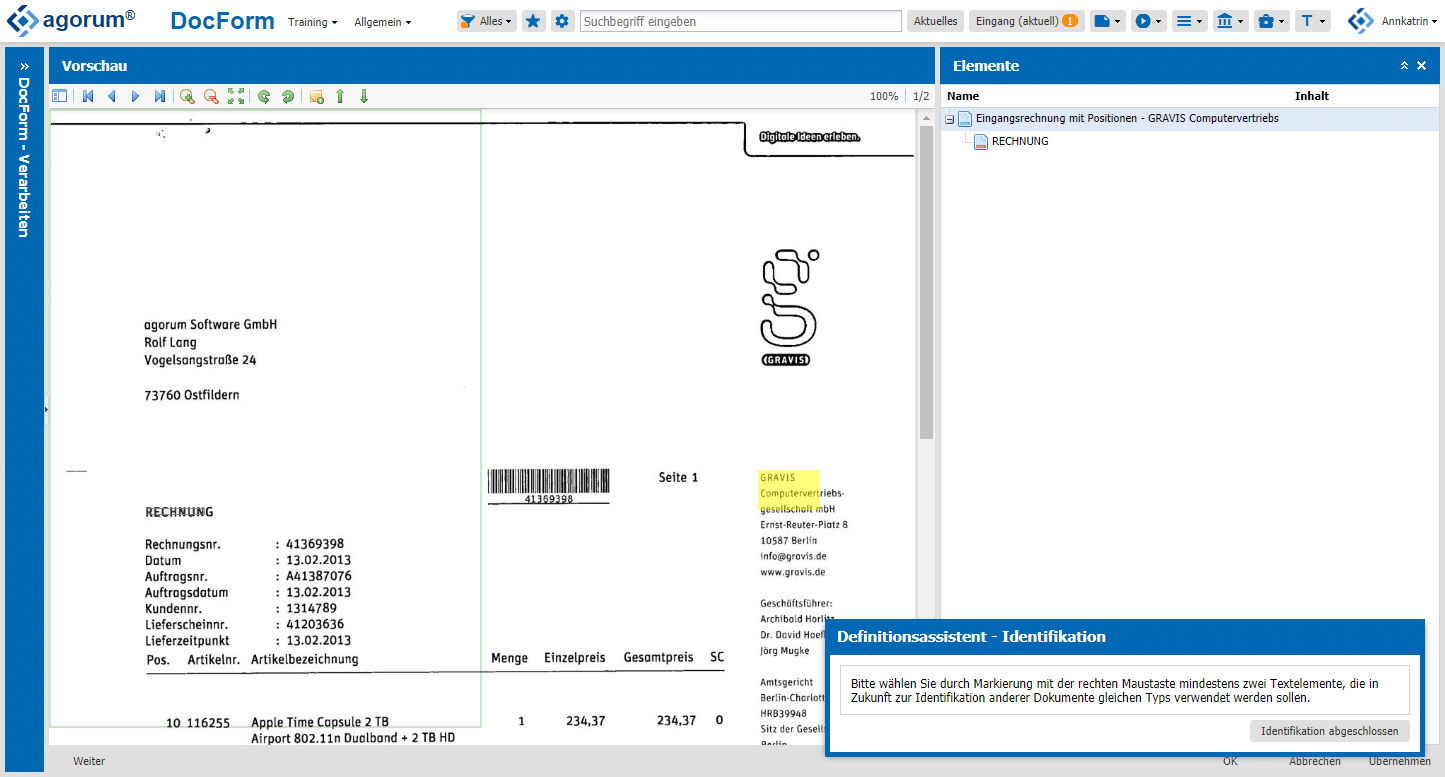
- Dokumentenherkunft auswählen
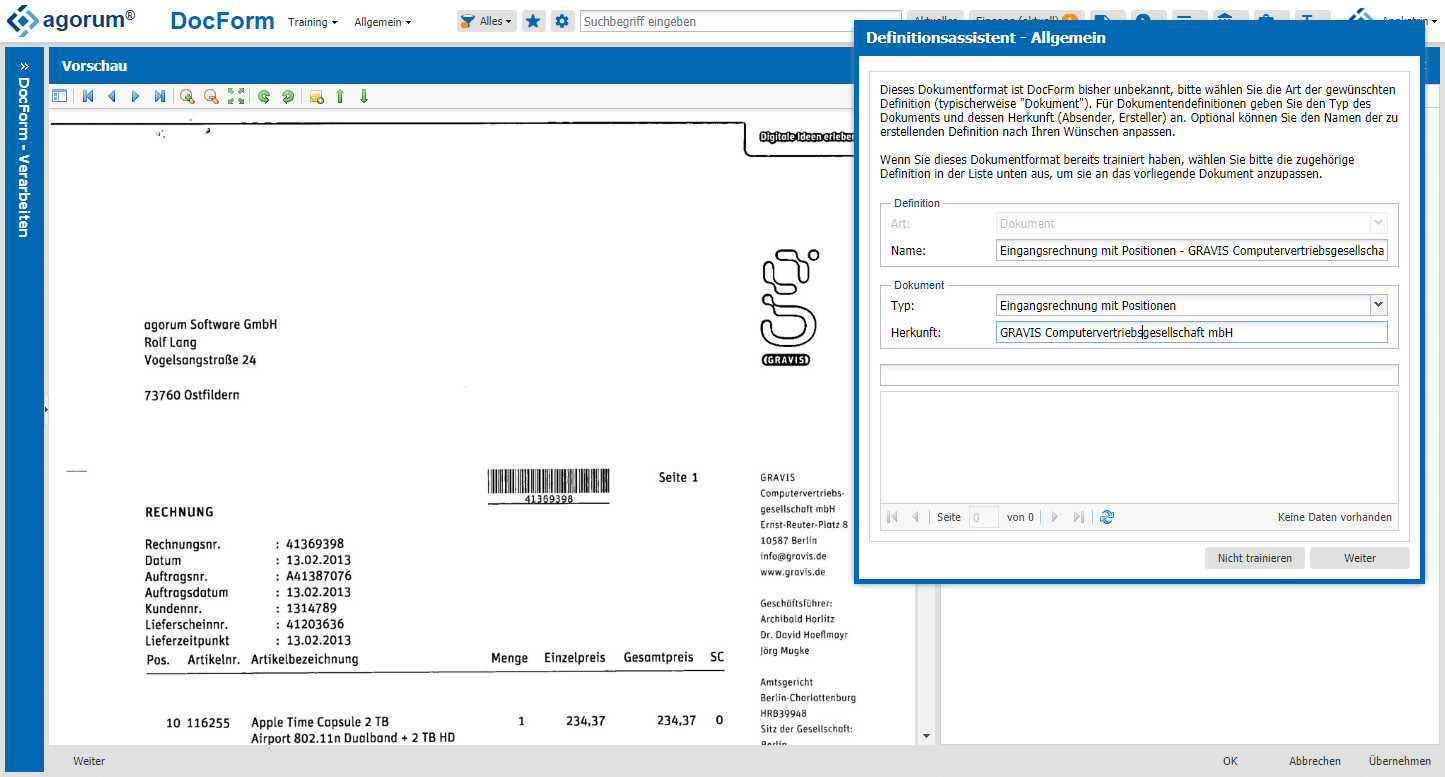
Das zweite Kriterium, das definiert wird, ist die Herkunft: Woher stammt dieses Dokument? In diesem Beispiel stamm es von der Firma “Gravis”. Den Begriff kann ich auch direkt mit der rechten Maustaste aus dem Dokument herauslesen.
Bei einem Klick auf “Weiter” startet der Trainingsassistent.
Zuerst werden mindestens zwei eindeutige Merkmale definiert, damit docform das nächste Mal weiß, dass es diese Definition nutzen soll. In diesem Beispiel markiere ich mit der rechten Maustaste einmal das Wort “Rechnung” und das Wort “GRAVIS”. Wenn also irgendwo in den grün definierten Bereichen die beiden Worte stehen, dann handelt es sich um eine Rechnung von diesem Lieferanten.
Ein Klick auf “Weiter” führt mich nun schrittweise durch die Abfrage der einzelnen Metadaten wie beispielsweise Rechnungsnummer, Rechnungsdatum, aber auch die Positionsdaten.
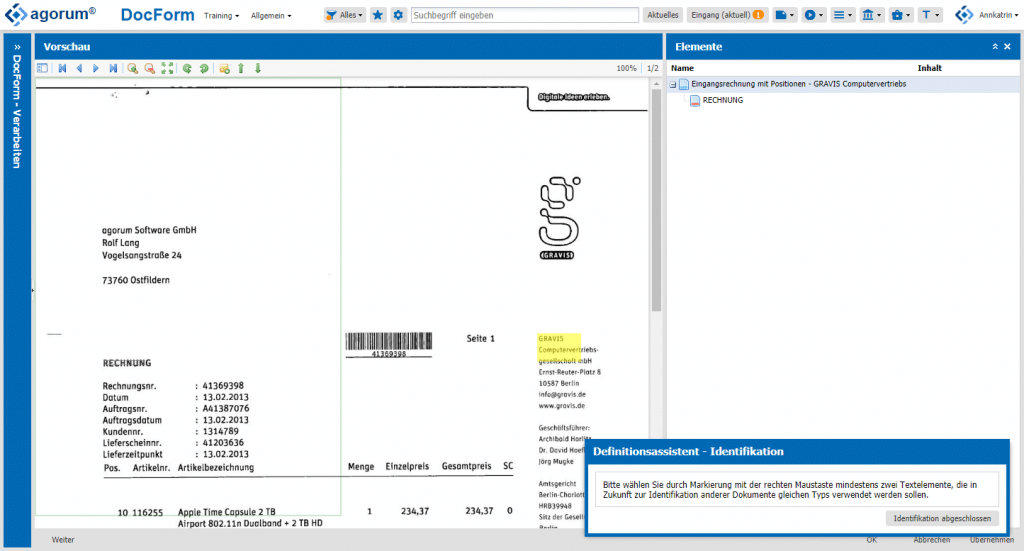
Dabei arbeitet docform mit einem sehr flexiblen Definitionsmodell, bei dem die gesuchten Informationen nicht exakt an den definierten Stellen liegen müssen. Für das Beispiel mit der Rechnungsnummer sucht das System in dem grün definierten Bereich nach dem Wort “Rechnungsnr.” und leist dann relativ dazu die Rechnungsnummer aus. Dabei wird mit einer Fuzzy-Logik vorgegangen, sodass das Wort “Rechnungsnr.” nur ähnlich geschrieben sein muss.
Somit funktioniert die Erkennung auch, wenn ein Dokument verschoben gescannt wird oder der Lieferant die Rechnungsinformationen geringfügig umformatiert.
8.) Positionsdaten auslesen
docform fragt nun ein definiertes Metadatum nach dem anderen ab, bis alle Metadaten erfasst sind. Das dauert in der Regel nur 1-2 Minuten pro Dokument und muss für jeden Lieferanten nur einmalig durchgeführt werden.
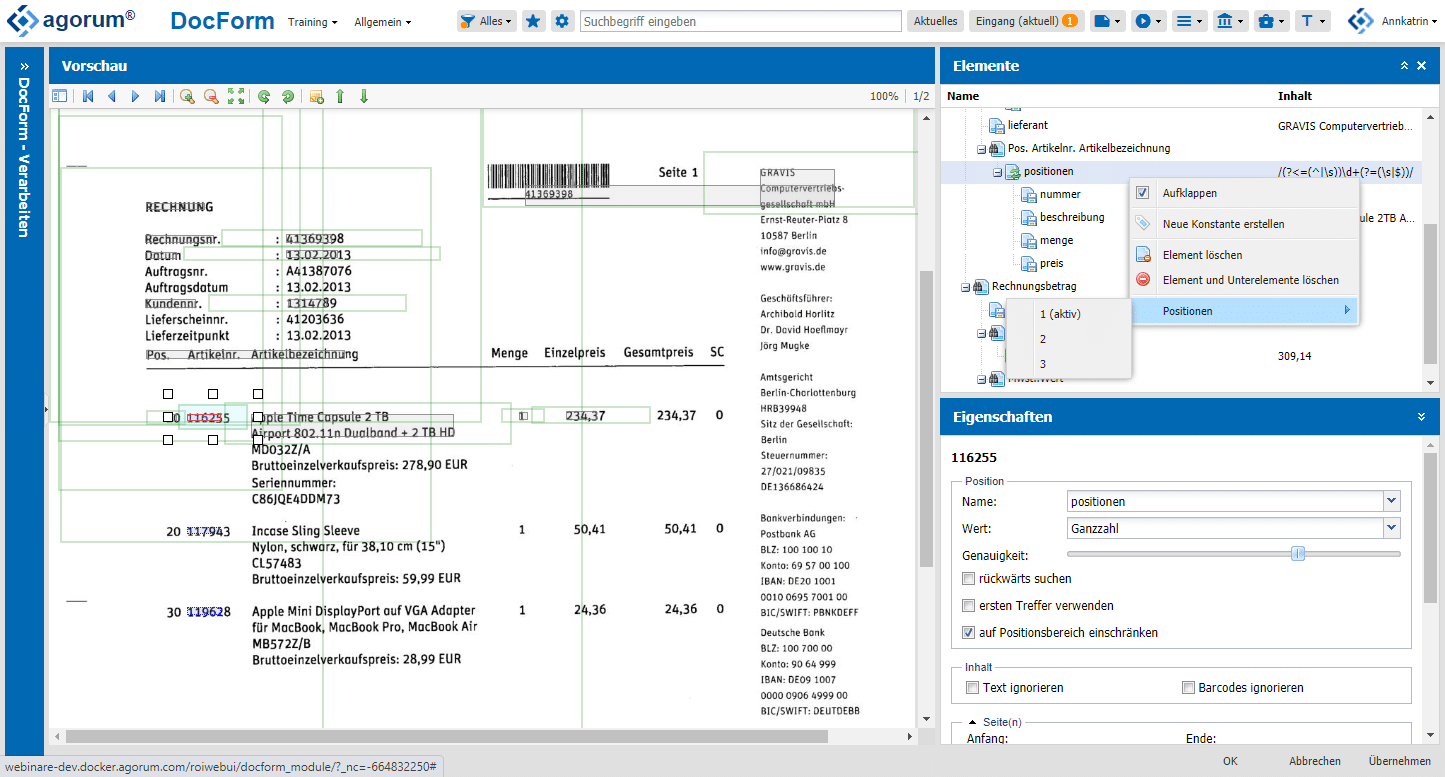
docform ist dabei auch in der Lage, wiederholende Informationen in Listenform auszulesen wie beispielsweise die einzelnen Positionen einer Rechnung. Dabei wird automatisch ein Muster ermittelt, dass sich in den einzelnen Positionen wiederholt. In diesem Beispiel ist es die Artikelnummer.
Bei einem Klick auf “OK” ist das Training abgeschlossen. Ab sofort werden Rechnungen dieses Lieferanten vollautomatisch erkannt und erfasst – so einfach geht das!
9.) Automatisch erfasste Dokumente manuell prüfen
Es ist auch möglich, ein Dokument nach der automatischen Erkennung noch einmal von Hand zu prüfen.
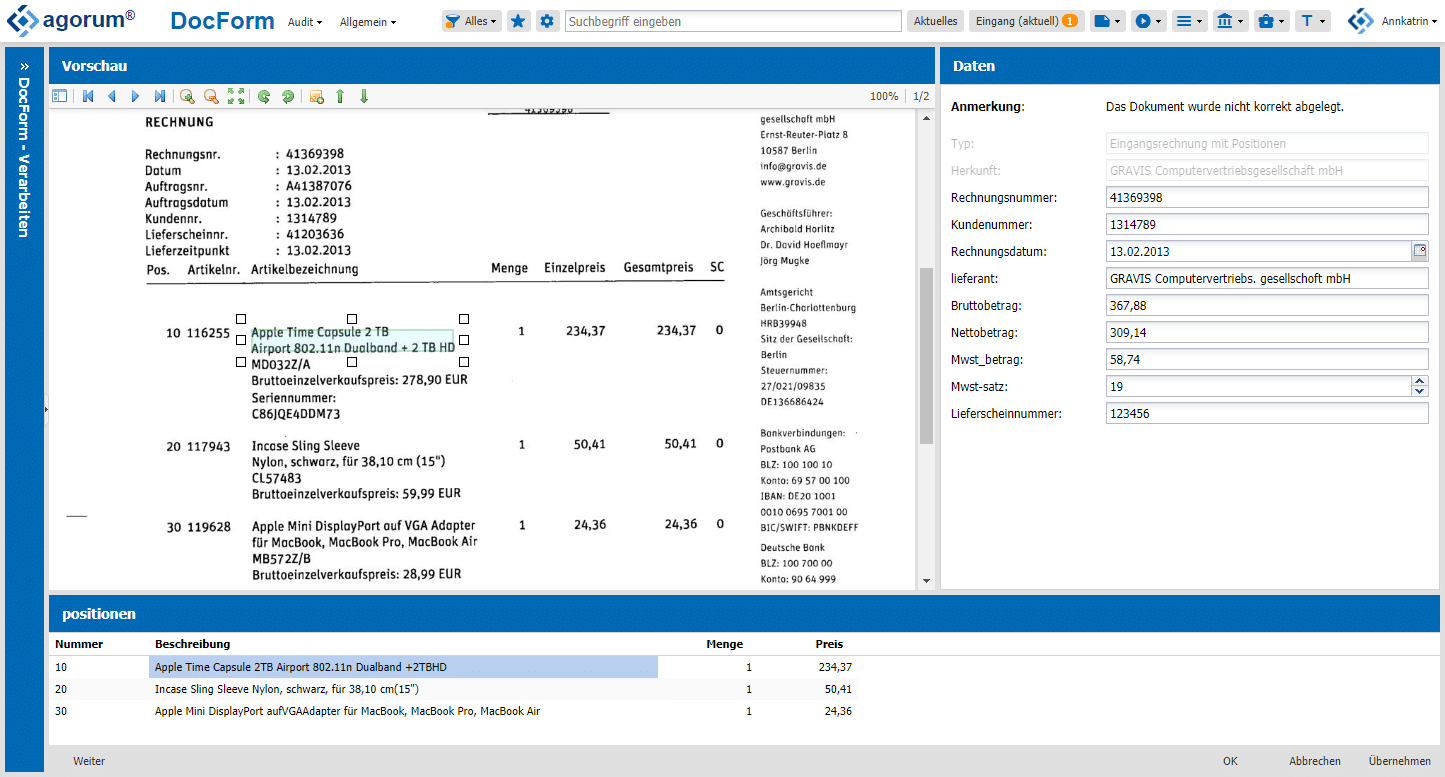
- Dabei wird das Dokument in docform im Status “Audit” dargestellt. Auf der rechten Seite sehe ich alle erkannten Metadaten, im unteren Bereich hingegen alle Positionen. Klicke ich auf eine Position, so wird diese direkt im gescannten Dokument hervorgehoben.
- An dieser Stelle könnte ich auch eine Kontierung der einzelnen Positionen durchführen. Das kann sogar so konfiguriert werden, dass die Kostenstellen direkt aus einer Datenbank gelesen und angeboten werden.
- Auch eine vollautomatische Validierung der Rechnungsinformationen kann erfolgen. Beispielsweise ein Abgleich mit einer Bestellung im ERP oder die Prüfung der Summe der einzelnen Positionen mit dem Nettowert der Rechnung und vieles andere mehr. Somit müssen Rechnungen nie wieder von Hand nachgerechnet werden.
10.) Weiteres Vorgehen nach der Erfassung
Nun ist das Dokument gescannt, gespeichert und vollständig erfasst und geprüft worden. Was passiert danach? An dieser Stelle möchte ich kurz anreißen, welche Aktionen im Anschluss zum Beispiel folgen könnten:
- Mithilfe des agorum core fileworkflows kann das Dokument automatisch umbenannt und revisionssicher abgelegt werden. Dabei können die erkannten Metadaten genutzt werden, um die Benennung und Ablage zu definieren.
- Es können Freigabeprozesse angestoßen werden, zum Beispiel ein mehrstufiger Rechnungsfreigabe-Workflow.
- Die erfassten Informationen können an ein anderes System übergeben werden, zum Beispiel an DATEV, allgemein als ZUGFeRD, als CSV- oder auch als XML-Datei – inklusive der Positionsdaten und Kontierungsinformationen.
- Es können automatische Skripte aufgerufen werden, um automatisierte Prozesse anzustoßen.
Es sind weitere Aktionen möglich, fragen Sie gerne bei uns nach!
FAZIT: Dokumentenmanagement mit Scanbot verbinden
Sie sehen, wie einfach Scanbot mit dem Dokumentenmanagement-System agorum core verbunden werden kann und wie mächtig die darauffolgende automatisierte Verarbeitung stattfinden kann.
Ist alles einmal eingerichtet, muss der Benutzer nur noch das Dokument scannen. Alles weitere passiert vollautomatisch im Hintergrund. Mehr Best Practice Themen finden Sie hier.